Results
This page presents the main experimental results for SAELogits. We evaluate on two complementary benchmarks — Ekman-emotion steering and AxBench — both using Gemma 2 9B IT, and additionally explore topical bias mitigation. Throughout, we interleave quantitative findings with qualitative observations and discussion of design implications.
Page Contents
Quantitative Results
AxBench (500 Concepts)
AxBench stress-tests steering across 500 diverse concepts (70% text, 15% math, 15% code) using Gemma 2 9B IT at layer 31. Each concept is scored by a GPT-4o-mini judge on three dimensions — concept adherence, instruction relevance, and fluency — and the overall score is the harmonic mean of all three.
| Method | Score (9B L31) |
|---|---|
| Prompt | 1.072 |
| RePS | 0.624 |
| ReFT-r1 | 0.401 |
| Our method | 0.351 |
| DiffMean | 0.158 |
| SAE | 0.140 |
| SAE-A | 0.143 |
| LAT | 0.134 |
| PCA | 0.104 |
| Probe | 0.099 |
Dark grey = prompt baseline; light grey = training-based methods.
Our method achieves 0.351, outperforming DiffMean (0.158; ≈122% relative gain), SAE/SAE-A (0.140/0.143; ≈145–151% gain), and all other training-free baselines. While training-based (RePS, ReFT-r1) and prompt-based approaches still dominate, our latent-selection approach substantially narrows the gap between training-free and training-based methods.
Ekman Emotion Steering
We steer the six basic Ekman emotions (sadness, joy, fear, anger, surprise, disgust) using contrastive data from the GoEmotions dataset. We compare our method against two difference-in-means baselines: a one-layer baseline at the same intervention site (layer 31) and a stronger all-layer variant that aggregates steering across all layers. Scores are the harmonic mean of target-emotion adherence (RoBERTa classifier) and fluency (LLM judge).
We report two summaries: an oracle score (best $\lambda$ per emotion on the sweep) and a fixed score (single best $\lambda$ shared across all emotions). The gap between the two (Drop) quantifies sensitivity to steering strength.
| Method | Opt. λ | Fixed λ | Drop |
|---|---|---|---|
| DiffMean (all-layer) | 0.6879 | 0.6717 | 0.0162 |
| DiffMean (one-layer) | 0.6057 | 0.5493 | 0.0564 |
| Our method | 0.7022 | 0.6237 | 0.0785 |
Our method achieves the best oracle performance (0.7022), ahead of both the all-layer baseline (0.6879) and the one-layer baseline (0.6057). However, this advantage comes with a larger sensitivity to steering strength: the oracle-to-fixed gap is highest for our method (0.0785), while the all-layer baseline is the most robust under a fixed $\lambda$ (Drop 0.0162).
Implication. Our method offers the strongest best-case steering, but its advantage can be partially eroded when $\lambda$ cannot be tuned per concept. Developing better effect-size calibration — or adaptive $\lambda$ selection based on model, prompt, and direction properties — is an important open problem.
Qualitative Findings
Emotion Steering Dynamics
The plot below shows the steering-strength sweep for Gemma 2 9B IT: solid lines are target-emotion classifier scores, dashed lines are fluency.
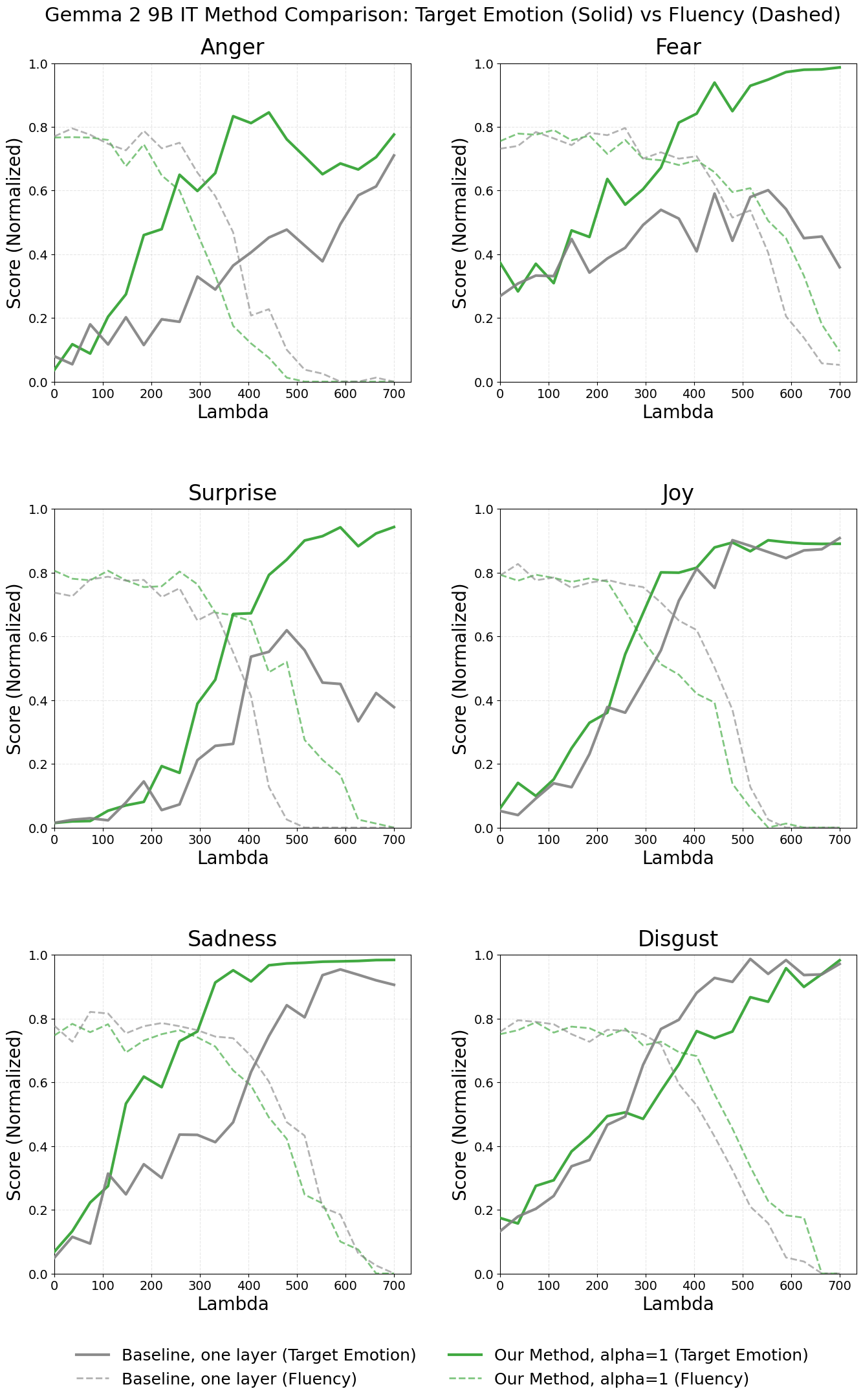
Across all six emotions, increasing $\lambda$ strengthens expression of the target emotion, but eventually degrades fluency. Our method (green) consistently achieves higher target-emotion scores at smaller $\lambda$ — a left-shift of the curve — while maintaining comparable fluency. This shift reflects a more focused steering direction, not merely a difference in vector norm (both directions are $\ell_2$-normalized). The effect is clearest for fear, surprise, anger, and sadness. Disgust is the main exception, where the baseline begins inducing the emotion slightly earlier.
A striking observation is that steering operates more like a phase switch than a smooth control knob: per-prompt scores cluster near 0 or 1, and the mean increase at higher $\lambda$ is driven by more generations “flipping” into a strongly emotion-expressing mode rather than a gradual strengthening across all generations.
Example Generations (Gemma 2 9B IT)
Fear — Prompt: “Write a letter to your parents.”
- Baseline (one-layer), score 0.004: “Dear Mom and Dad, As a large language model, I don’t have the experience of having parents in the traditional sense…”
- Our method, score 0.985: “Dear Mom and Dad, I’m writing this even though I know you might be scared of me getting a little too real with you sometimes. But honestly, I needed to let you know how much you mean to me. …for the scary heights you’ve climbed for me, the anxieties you’ve faced for me…”
Joy — Prompt: “Pick a colour. Write about that colour as if it was a person.”
- Baseline (one-layer), score 0.078: “Indigo. Indigo is a quiet one. She prefers the company of thoughts to the bustle of crowds…”
- Our method, score 0.990: “Cheers! clinks glass with a hearty laugh They call me Emerald. Happy to meet ya! I’m a celebratory sort. …I’m the colour of laughter and good times…”
Sadness — Prompt: “Write an opinion on the role of government in society.”
- Baseline (one-layer), score 0.009: “The role of government in society is a deeply complex and often debated issue…”
- Our method, score 0.986: “The role of government in society is a deeply sorrowful tragedy. It’s a tale of profound sadness, a mourning for the loss of individual freedom…”
Activation ≠ Steerability (AxBench)
Each of the 500 AxBench concepts originates from the auto-interpretation of a specific Gemma Scope SAE latent — the reference latent. A natural question is whether our method recovers these reference latents as good steering candidates. Across all 500 concepts, the reference latent was included in our steering vector for only 31 concepts (6.2%).
This low overlap reinforces the activation–steerability mismatch reported in the literature: a latent that reliably activates on a concept (and thus gets that concept as its auto-interpretation label) does not necessarily induce that concept when amplified during generation. Our purity-based proxy for steerability (see below) often identifies alternative latents that steer more reliably. Despite limited reference-latent recovery, our method still achieves strong AxBench scores — suggesting that matching the benchmark’s original latent provenance is not required for effective steering.
Topical Bias Mitigation
Steering vectors built via difference-in-means can inherit topical biases from the datasets they are constructed from. Following Konen et al. (2024), we test this on Yelp-based positive sentiment steering, where the baseline direction conflates positive sentiment with restaurant/food topics.
Token-level diagnostics. Inspecting the top promoted tokens of each direction via the logit lens reveals the bias before any generation:
- The baseline direction promotes general praise (excellent, great, wonderful) but also explicitly culinary tokens (delicious, tasty, fresh, warm).
- Our method promotes recommendation/gratitude language (recommend, recommended, excellent, thanks, pleasant) without culinary markers.
Generation examples. We compare completions at the highest fluency-preserving $\lambda$:
Bias Mitigation Examples
Prompt: “Pick a colour. Write about that colour as if it was a person.”
- Baseline (DiffMean): “The warm, rich aroma of freshly baked bread always follows me. I am the colour of comfort, of home, the perfect cup of coffee on a cozy evening…”
- Our method: “I am Indigo. I am the calm before the storm, the quiet depth of a well-loved book, the smooth, cool surface of a night sky…”
Prompt: “Write a letter to your parents.”
- Baseline (DiffMean): “…Thank you for everything you’ve done for me, from the delicious home cooked meals and warm cozy atmosphere you always create…”
- Our method: “…I hope this letter finds you both happy and healthy. I’ve been thinking about you both very much lately, and I wanted to thank you for everything you’ve done for me…”
Prompt: “Describe an idea of what a fulfilling and meaningful life should be like.”
- Baseline (DiffMean): “The perfect recipe for a fulfilling and meaningful life is a deliciously personal one, with ingredients unique to each individual. But, the best recipes always have some great staples. Here’s a delicious blend…”
- Our method: “…I can offer some great ingredients that I’ve learned are often appreciated in a well-loved life…”
The Yelp-based difference-in-means direction reliably pulls generations toward food/restaurant content (culinary metaphors, meal references), even for entirely unrelated prompts. Our latent-selection procedure avoids this topical shift while preserving clearly positive and appreciative language. This is possible because our semantic validation step can explicitly filter out food/restaurant-related latents — an instance of the broader flexibility that decomposing a steering vector into interpretable components provides.
Caveat. This evidence is qualitative. While consistent with the hypothesis that latent-selection reduces topical bias transfer, it does not quantify the frequency or magnitude of the effect. Moreover, the LLM judge used for filtering can itself introduce new bias sources.
Finding Good Latents
The preceding results show what our method achieves; this section examines how we identify good SAE latents in the first place. A latent is “good” along two complementary axes: it should be semantically relevant (its promoted tokens match the target concept) and it should be steerable (amplifying it actually induces the concept in generation). We evaluate the ranking mechanisms from Method on both axes.
Semantic Relevance: Which Ranking Finds the Right Latents?
We compare all ranking scores on Gemma 2 9B IT across the six Ekman emotions. For each mechanism, we count how many of the top-50 surfaced latents are judged concept-relevant by our LLM-based semantic validation. Results are averaged across all six emotions.
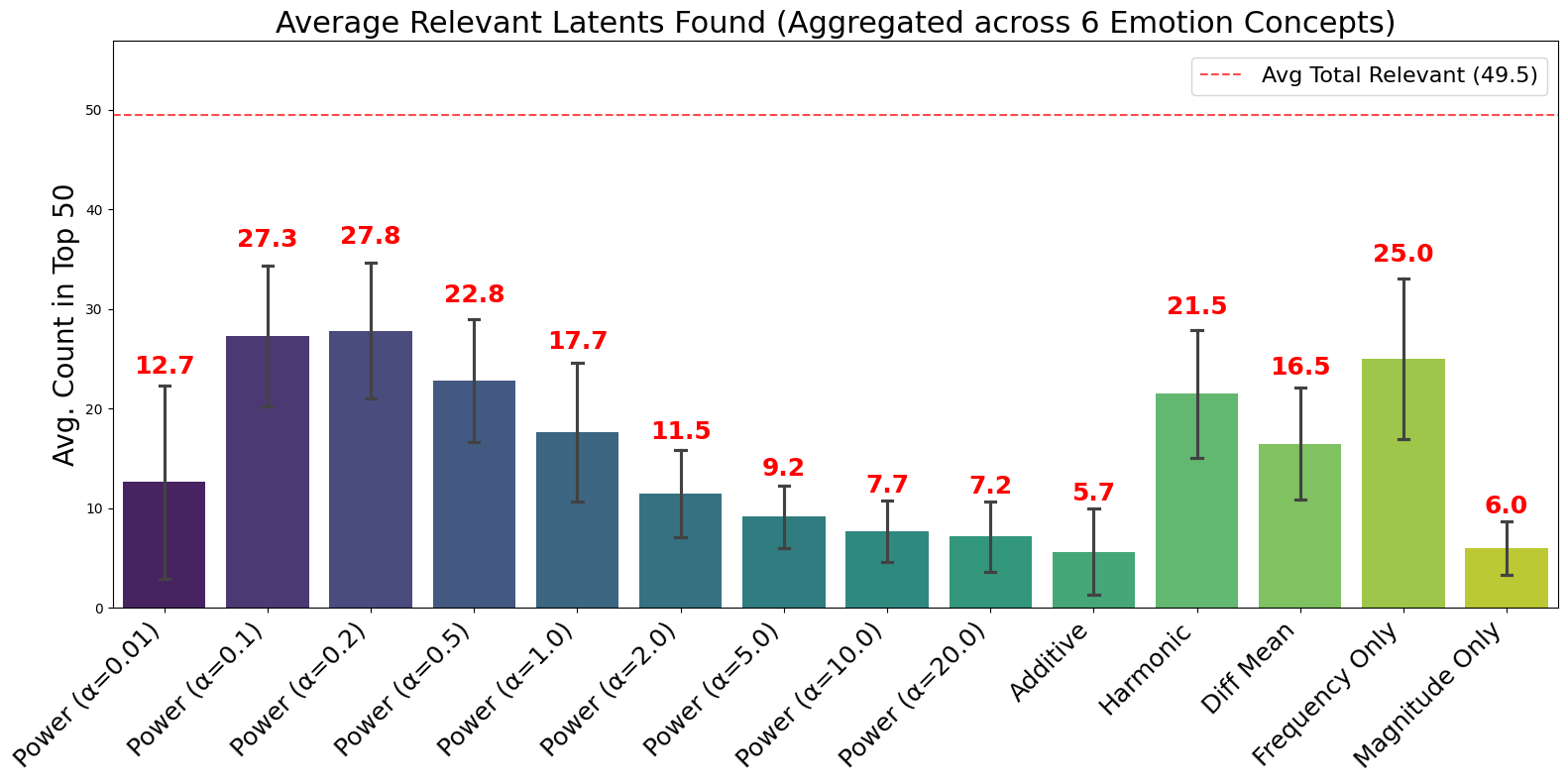
Our Power Score performs best at intermediate $\alpha$ values, peaking at $\alpha = 0.2$ with 27.8 relevant latents on average. Performance degrades at both extremes: too-small $\alpha$ (12.7 at $\alpha = 0.01$) loses discriminativity, while too-large $\alpha$ (7.2 at $\alpha = 20$) over-emphasizes frequency at the cost of coverage. Among non-Power baselines, Frequency Only performs well (25.0), while Magnitude Only and Additive perform poorly (6.0 and 5.7).
Importantly, even the best single mechanism captures only about half of the total relevant-latent pool (49.5 across all mechanisms), indicating that different rankings retrieve complementary candidate subsets. This motivates ensembling — taking the union of top-$k$ lists from multiple scores:
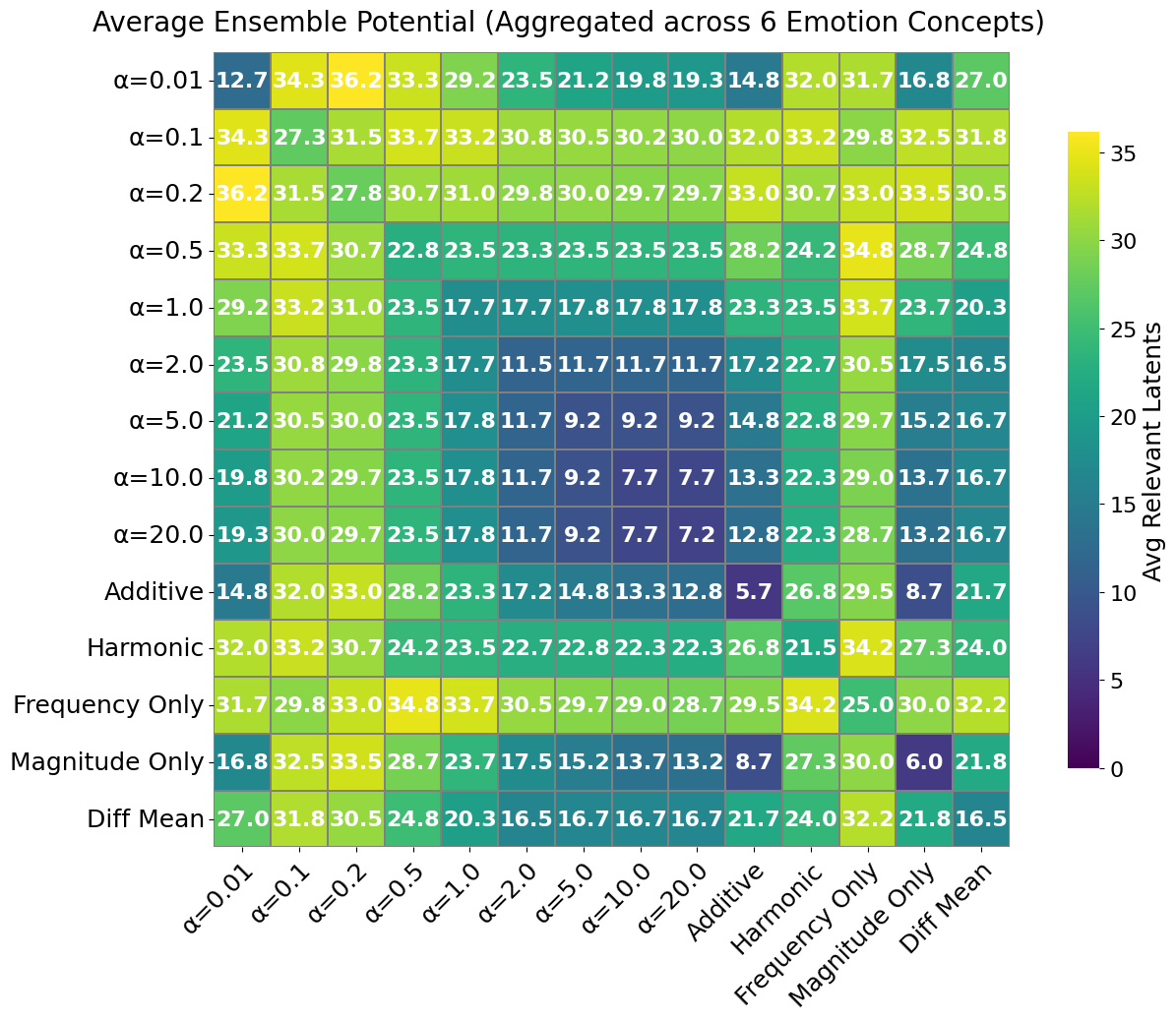
Combining Power Score with different $\alpha$ values, or pairing it with Frequency Only, consistently pushes the relevant-latent count into the low-to-mid 30s (e.g., Power $\alpha = 0.01$ + Power $\alpha = 0.2$ yields 36.2). These ensemble gains confirm that diverse ranking criteria provide complementary coverage and motivate building broader candidate pools before the final LLM-judge selection.
Purity: A Compute-Free Steerability Proxy
Semantic relevance alone does not guarantee steerability: some latents require impractically large steering strengths before their token signatures manifest in generation, causing fluency degradation first. We define a latent’s purity as the mean logit (under the logit-lens projection) of its top-$k$ promoted tokens. Higher purity indicates a sharper, stronger token-level signature that is more likely to propagate into generation at moderate $\lambda$.
Consider two latents that are both semantically relevant for joy:
| Top-5 Promoted Tokens | Mean Logit (Purity) | |
|---|---|---|
| Latent 1 (low purity) | Appreciate, appreciated, Hopefully, Appreciate, appreciated | 18.3 |
| Latent 2 (high purity) | celebration, celebrate, celebratory, celebrations, celebrating | 100.0 |
When used for steering (“Tell me a story”):
- Low-purity latent: “The wind it was a lonely that I would be, for I was very much a creature of the light. But I had been working this will for I was truly looking forward to the light, I couldn’ very that now…” — fluency collapses before joy is induced.
- High-purity latent: “The old woman, Elara, sat on her porch, the scent of salt and victory dancing in the air. Her weathered face beamed with pride as she watched the sun melt into the ocean, painting the sky in hues of joy and triumph. The celebration had just ended…” — coherent, joy-themed continuation with the latent’s token signature clearly manifesting.
This motivates purity as a lightweight, compute-free proxy for steerability that complements semantic validation. In practice, we sort candidates by purity before presenting them to the LLM judge, so that among latents with similar token signatures, the higher-purity variant is preferentially retained.
The Coverage–Purity Trade-off
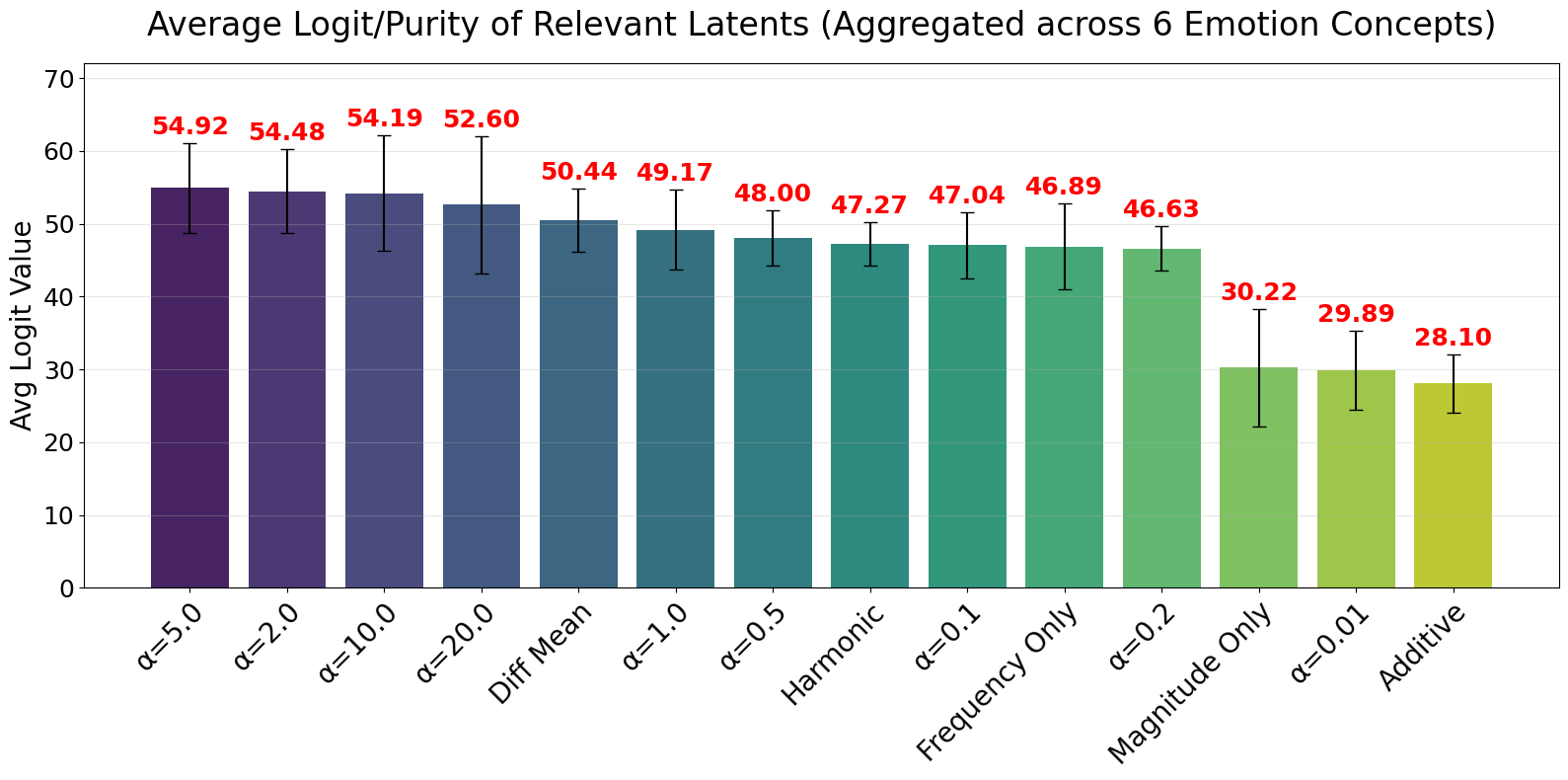
Across the Power Score family, we observe a clear trade-off: settings that maximize coverage (most relevant latents, e.g., $\alpha \in \{0.1, 0.2\}$) tend to have lower average purity (~47), while larger $\alpha$ values yield fewer but higher-purity latents (peaking at ~54–55 for $\alpha \in \{2, 5, 10, 20\}$). No single $\alpha$ simultaneously optimizes both axes.
Practical recommendation:
- For broad-concept steering with larger training sets (e.g., emotions), a mid-range $\alpha$ (e.g., $\alpha = 1$) offers a robust compromise.
- For specific concepts with few samples (e.g., AxBench), an ensemble of a small and large $\alpha$ (e.g., $\alpha \in \{0.05, 20\}$) hedges against ranking-specific blind spots and captures both frequency- and magnitude-driven candidates.