SAELogits — SAE Assisted Contrastive Steering
Luka Gerlach · luka.gerlach@gmx.de
This page accompanies my master’s thesis at the University of Cologne and the German Aerospace Center (DLR) and serves as a results overview while the full paper is in preparation.
SAELogits is a training-free method for constructing interpretable steering vectors for LLMs. Rather than learning a direction directly in activation space, we identify SAE latents whose activation patterns are characteristic of a target concept, validate them semantically, and combine their decoder directions into a final steering vector. Our main contributions are as follows:
- Improved Steerability: We find our method can improve concept induction at equal/better model capability compared to other training-free methods.
- Transparency: We define a steering vector as a weighted sum of SAE latents, giving us a better idea of what our steering vector actually promotes (see examples below).
- Latent Selection Criterion: We propose a new criterion for selecting SAE latents for steering, combining semantic relevance (via logit-lens token signatures) with a compute-free steerability proxy (mean logit of promoted tokens), addressing the known mismatch between auto-interpretability explanantions and causal influence of SAE features. We compare several candidate-selection strategies against this criterion.
- Topical Bias Mitigation: We find that our approach is able to mitigate dataset-induced topical biases in learned steering directions. Whereas a standard difference-in-means vector built from Yelp reviews conflates positive sentiment with restaurant- and food-related topics, our latent-selection procedure filters out bias transfer while preserving the intended sentiment effect.
For a detailed breakdown of all experiments, qualitative findings, and design analyses, see the full Results page.
Key Results
We evaluate our method on two benchmarks, both using Gemma 2 9B IT. First, we adopt the benchmark from another DLR Paper concerned with steering Ekman’s six basic emotions. To see how well our method generalizes to a larger pool of concepts to steer, we evaluate our method on Stanford’s AxBench benchmark that evaluates performance across 500 steering scenarios (see our AxBench Fork here). Across both benchmarks, our approach significantly outperforms other training-free methods.
AxBench Steering (Gemma 2 9B IT, L31)
| Emotion Steering (Gemma 2 9B IT)
|
Example Completions (Gemma 2 9B IT, Gemmascope)
The completions below are generated by Gemma 2 9B IT steered with our method. Each emotion includes a Steering Vector Composition panel showing exactly which SAE latents are active in the vector and what token-level concepts they encode.
Select a prompt and emotion:
Pipeline at a Glance
The following briefly describes how we construct a steering vector. For the analysis and design choices that emerged along the way, see Method and Results.
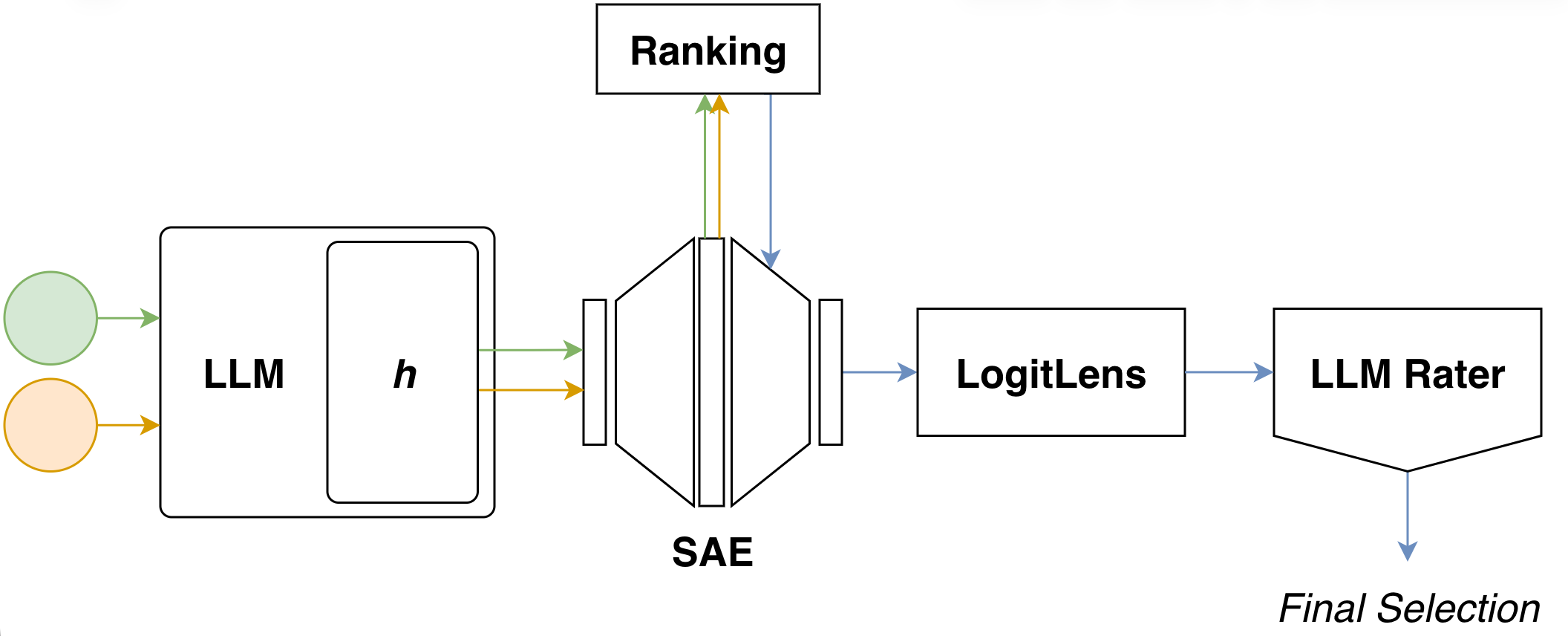
At its core, our approach builds a steering vector in five sequential steps:
- Activation Extraction — feed contrastive prompt pairs (positive / negative) into the base LLM and collect residual-stream activations at a chosen layer.
- SAE Encoding — project these activations into the corresponding SAE latent space to obtain sparse representations for both sets.
- Latent Ranking — score each SAE latent by how distinctively it activates on the positive set relative to the negative set, and keep the top-k candidates.
- Logit Lens Projection — decode each candidate latent back into vocabulary space via the logitlens to obtain a human-readable token signature.
- Semantic Validation — pass the token signatures to an LLM judge, which filters and reranks candidates by semantic fit and combines the selected decoder directions into the final steering vector.